
The Boxer
B tree, B+ tree 본문
B tree
B tree는 root에서 leaft 노드 까지 모든 path의 길이가 동일한 tree 이며, Balanced 의 약자를 사용하여 B tree라 합니다. 인덱스를 조직하는 용도로 사용되며, m-원 탐색 트리로 키 값을 효율적으로 탐색할 수 있습니다.
m-way search tree
- m-원 탐색 트리(m-way search tree) 혹은 다원 탐색 트리(multi search tree)라고도 합니다.
- 다원 탐색 트리는 하나의 노드가 최대 m개의 서브 트리를 가질 수 있습니다.
- 이진 탐색 트리는 m=2인 m-원 탐색 트리로 볼 수 있습니다.
특징
B tree는 탐색을 효율적으로 하기 위한 몇 가지 특징이 있습니다.
- 높이가 h인 m-원 트리는 최대 m^h - 1 개의 키 값을 저장할 수 있습니다.
- 이진 탐색 트리의 경우 m=2를 만족하며, h=3인 경우 최대 7개의 키 값을 저장합니다.
- m=4 이고, h=3인 경우 최대 63개의 키 값을 저장합니다.
- 한 노드가 갖고 있는 키 값 갯수가 k인 경우 1 <= k <= m 를 만족합니다.
- 각 노드의 키 값은 왼쪽부터 정렬된 상태를 유지합니다.
- k개의 키 값을 갖는 노드의 경우 k+1 개의 서브 트리를 갖습니다.
- 각 노드의 i번째에 저장된 저장된 키(Ki) 값보다 왼쪽에 위치하는 서브 트리의 모든 키 값들은 Ki 보다 작으며 오른쪽에 위치하는 모든 키 값들은 Ki보다 큽니다.
- root와 leaf 노드를 제외한 모든 모드는 내부 노드(internal node)라 합니다.
- 내부 노드는 최소 m/2 최대 m개의 서브 트리를 가지며, m/2 - 1 개의 노드를 갖습니다.
- m/2 인 이유? 트리 전체의 노드 갯수가 많아져 트리의 높이가 높아지는 경우 탐색 속도가 저하 될 수 있습니다. 이를 방지하기 위해 최소 서브 트리 갯수를 지정합니다.
- 내부 노드는 최소 m/2 최대 m개의 서브 트리를 가지며, m/2 - 1 개의 노드를 갖습니다.
- root가 그 자체로 leaf가 아니라면 최소 2개 이상의 자식 노드를 갖습니다.
- 모든 leaf 노드는 같은 레벨이어야 합니다.
m = 4, h = 3인 경우

- m = 4, h = 3인 m원 트리 예시를 봅시다
- 모든 leaf 노드는 같은 레벨에 위치하며, 총 leaf 노드 갯수는 16개 입니다.
- 각 노드에 저장할 수 있는 키 값은 총 3개이며, 총 노드 갯수는 21개 이므로 총 63개의 키 값을 저장할 수 있습니다.
- 한 노드에서 3개의 키 값을 저장할 수 있으며, 총 4개의 자식 노드를 가질 수 있습니다.
노드 구조

하나의 노드는 다음과 같은 구조를 갖습니다.
- m: Btree의 차수
- Pi: 자식 노드에 대한 포인터
- Ki: 하나의 노드의 i번째 키 값
노드의 키 값과 포인터 관계에 대해
i번째 키 값인 Ki의 왼편에 위치한 포인터 Pi 가 가리키는 서브 트리의 키 값은 모두 Ki 보다 작으며, 오른쪽에 위치한 서브 트리의 모든 값은 Ki 보다 큽니다.
m=4 인 경우

- P1, P2, P3, P4: 자식 노드의 포인터가 저장됩니다. m=4인 경우 m개의 자식 노드를 갖습니다.
- K1, K2, K3: m=4인 경우 최대 3개의 키 값을 저장합니다.
탐색
n개의 데이터가 저장된 B tree의 경우 하나의 키 값을 탐색하는데 총 O(log(n))의 시간이 소요됩니다.
탐색은
- root에서 찾고자 하는 키 값이 위치한 노드의 높이까지 내려가는 로직
- 노드에서 키 값을 찾는 로직
두가지로 구성됩니다.
최악의 경우를 가정하여 키 값이 leaf노드에 있다고 가정합니다. B tree의 높이는 log(n) 이고, 각 노드에 m개의 데이터가 있다고 가정하면, 1. 에 대해 log(n), 2. 에 대해 log(m) 만큼의 시간이 소요되어 총 log(n) * log(m) 의 시간이 소요됩니다. 일반적으로 n >> m 이므로 탐색에 대한 시간복잡도는 O(log(n))이 소요됩니다.
2. 가 O(log(n))이 소요되는 이유
노드에서 데이터를 탐색하므로 선형 시간(n)이 걸릴 것이라고 생각할 수 있지만, B tree는 한 노드의 키 값 들이 정렬된 상태를 유지하므로 이진 탐색을 통해 키 값을 탐색할 수 있습니다.
삽입
- btree는 위에서 설명한 특징(정렬된 상태, leaf 노드 동일 레벨)을 유지해야 되므로 삽입 과정이 조금 복잡합니다.
삽입 과정
- 삽입 위치: leaf 노드. leaf 노드에 키 값이 들어갈 만한 적절한 위치를 탐색하고 삽입합니다.
- overflow가 발생시: 노드를 2개로 나누고 m/2 번째 인덱스의 키 값을 상위 노드로 올립니다.
- 상위 노드로 올리는 프로세스가 계속되어 root에서 overflow가 발생하면, root 노드를 둘로 나누고 tree의 높이를 증가시킵니다.
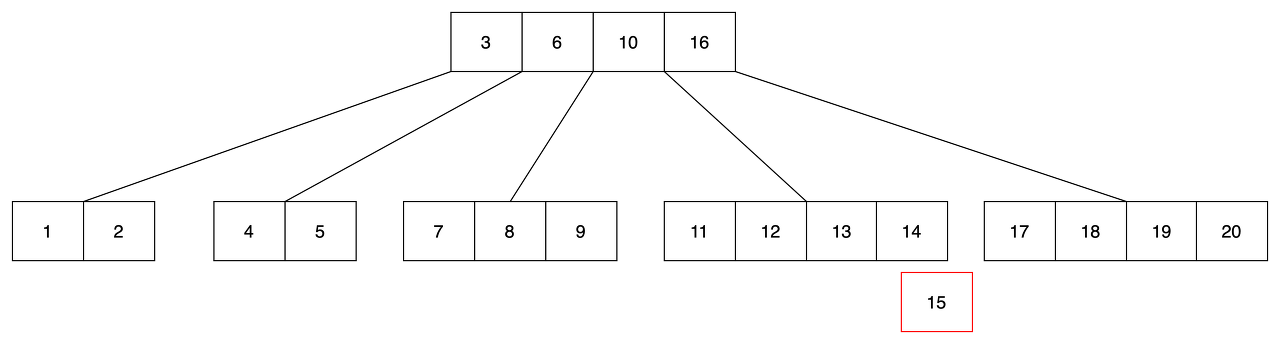
- m=4 인 btree를 예시로 봅시다. 위 그림에서 15라는 키 값이 추가되는 상황입니다.
- btree는 정렬된 상태를 유지해야 하므로 leaf 노드에서 들어갈 만한 자리는 4번째 노드입니다.
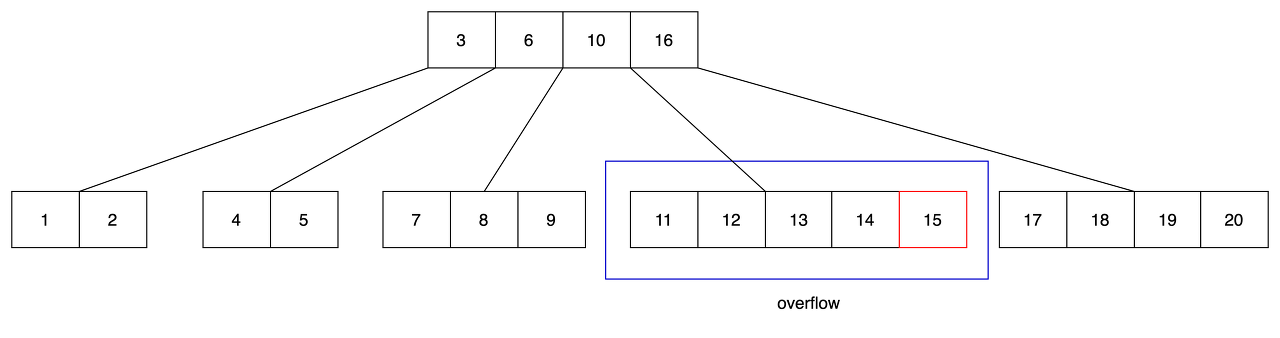
- 4번째 노드에 삽입한 경우 overflow가 발생합니다.

- overflow가 발생하여 노드를 둘로 나눕니다.
- m/2 = 2번 인덱스에 위치한 13을 상위 노드(root)로 올립니다.
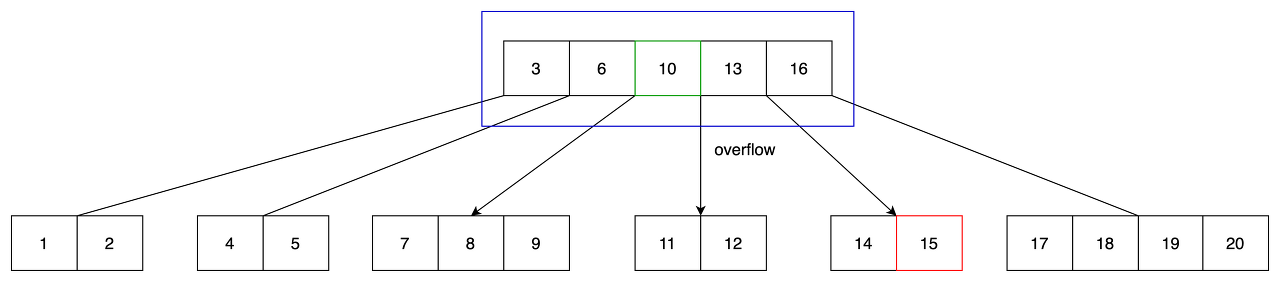
- root에 13을 올리면 root에서도 overflow가 발생합니다.
- root에서 overflow가 발생했으므로, 노드를 둘로 나누고 tree의 높이를 증가시킵니다.
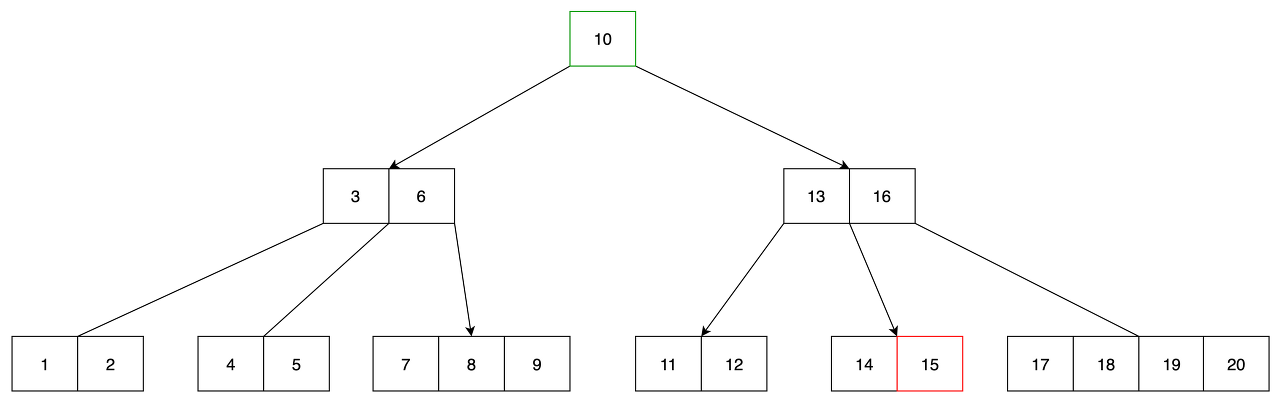
- m/2 번째 인덱스인 10을 상위로 올리면서 tree의 높이를 증가시킵니다.
삭제
- 삭제 과정 또한 btree의 특징을 유지해야 하며, 삽입 과정에 비해 조건에 따라 삭제 방법이 달라 조금 복잡합니다.
삭제 과정
- 삭제 위치: leaf 노드.
- 삭제해야 되는 값이 leaf 노드에 있다면 그대로 삭제합니다.
- 만약 삭제해야 되는 값이 leaf 노드에 있지 않다면, 해당 키의 바로 이전 값과 다음 값 중 하나를 선택하여 위치를 교환하고 삭제합니다.
- 해당 값의 이전 값 혹은 다음 값은 leaf 노드에 위치하므로, 위치 교환 이후에는 leaf 노드에 있는 값을 삭제하게 됩니다.
- ex) 11, 12, 13 이 저장되어 있는 경우 12를 삭제해야 한다면, 11과 13중 하나를 선택하여 12를 삭제 후 12의 위치로 옮김
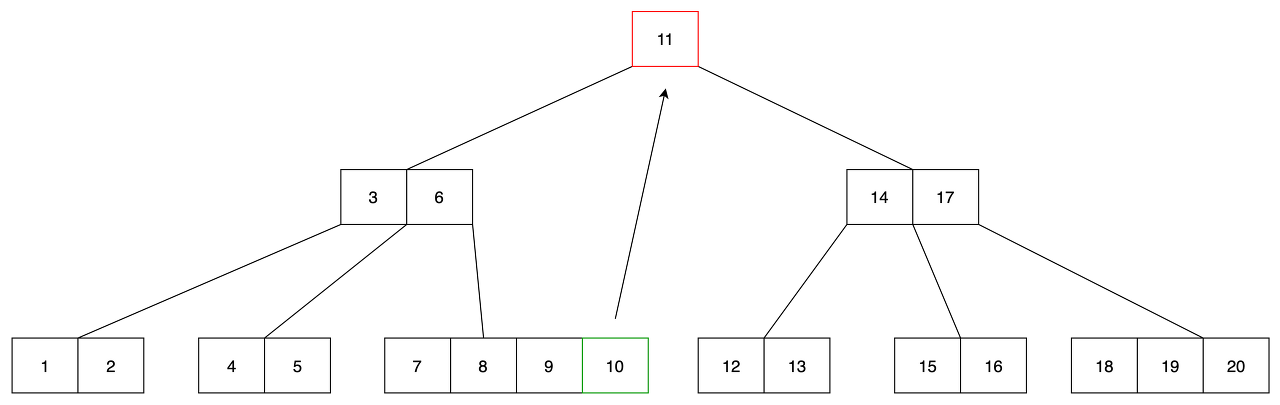
- 11을 삭제하는 경우를 봅시다. 이전 값인 10을 leaf 노드에서 찾습니다.
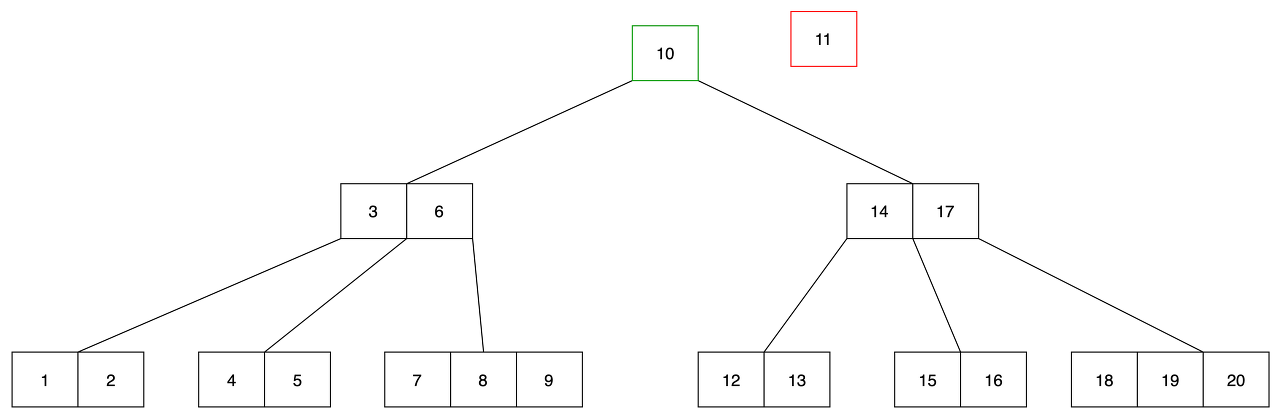
- 11을 삭제하고 10을 기존 11의 위치에 위치시킵니다.
이전(transfer)
- 만약 삭제 후 leaf 노드에 underflow가 발생하면(m/2-1개의 키 값을 갖게 된다면) 인접한 형제 노드에서 키를 추가할 노드를 찾습니다.
- 인접한 형제 노드가 m/2(최소 키 갯수) 보다 많은 갯수 개의 키 를 보유하고 있다면, 해당 노드의 키를 부모 노드로 이동하고, 부모 노드의 키 하나를 undeflow가 발생한 노드로 이동시킵니다.
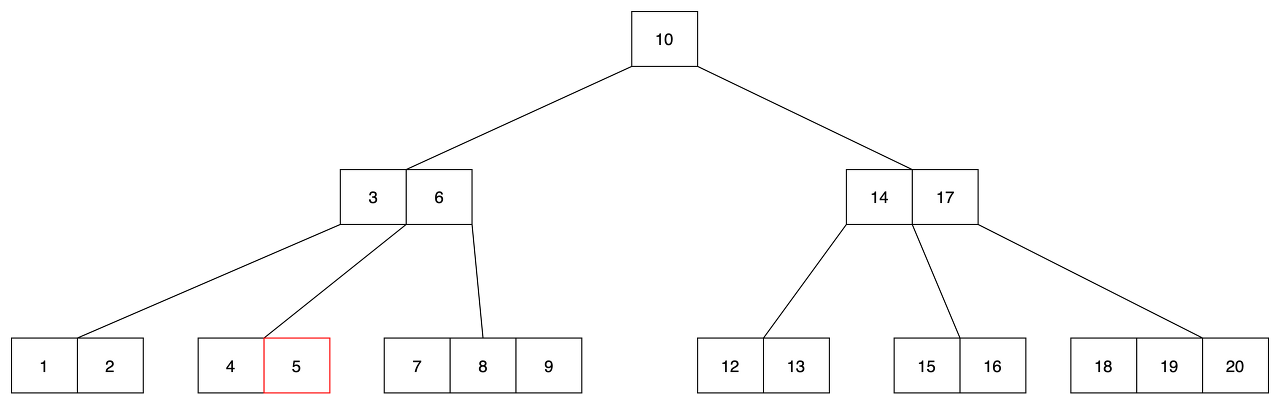
- 5를 삭제하는 경우입니다. 5를 삭제할 경우 leaf 노드의 2번째 노드는 최소 키 갯수를 만족하지 못하게 됩니다.
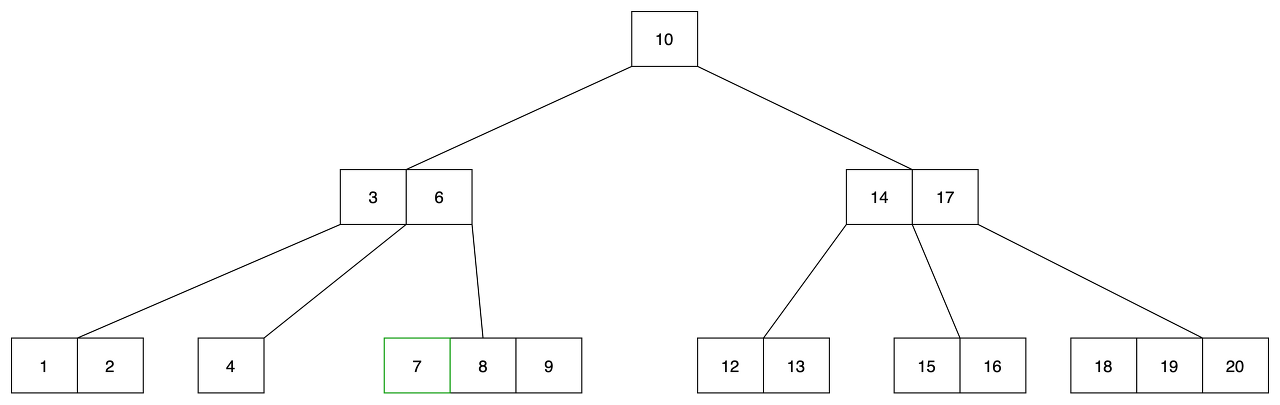
- 인접한 형제 노드에서 최소 키 갯수 보다 많이 키를 가진 노드에서 7을 이전 시킵니다.
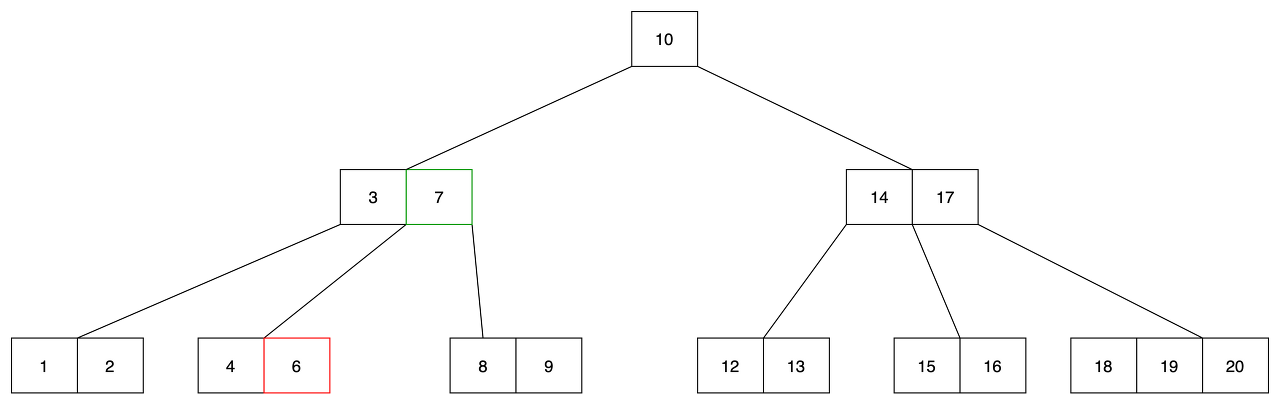
- 7을 부모 노드로 이동 -> 부모 노드의 6을 undeflow로 내립니다.
합병(fusion)
- leaf 노드의 인접한 형제 중 최소 키 갯수 보다 많은 키를 보유한 노드가 없다면, 형제 노드 + 부모 노드의 키 + undeflow가 발생한 노드를 합병합니다.
- 합병을 진행할 때 부모 노드의 키를 하나 빼게 되는데 이 과정에서 부모 노드의 키가 최소 키 갯수를 만족하지 않게 되는 경우 이 과정을 root 까지 반복합니다.
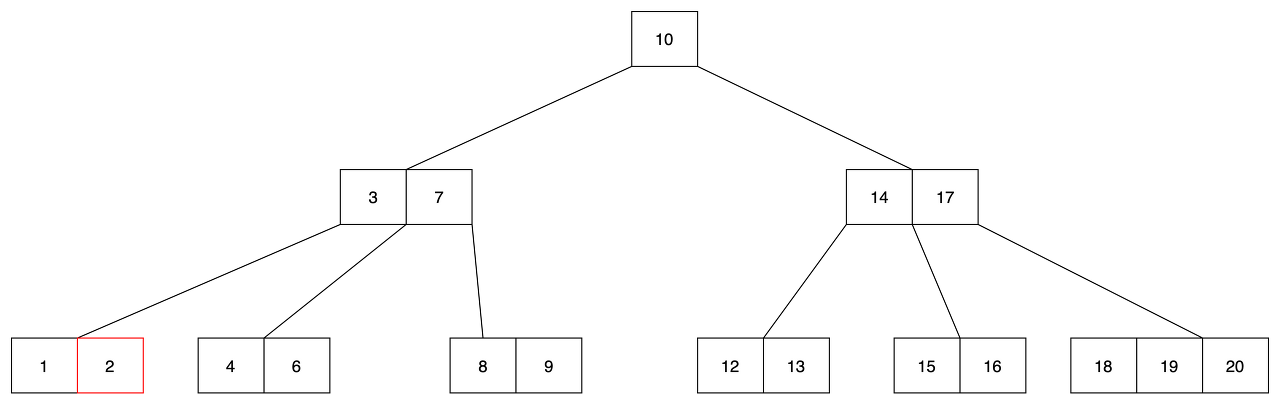
- leaf 노드의 2를 삭제 한다고 가정합니다.
- 2를 삭제할 경우 leaf의 첫번째 노드의 키 갯수가 1개가 됩니다. 또한, 인접한 노드의 키 갯수도 2개라 이전 또한 불가능합니다.
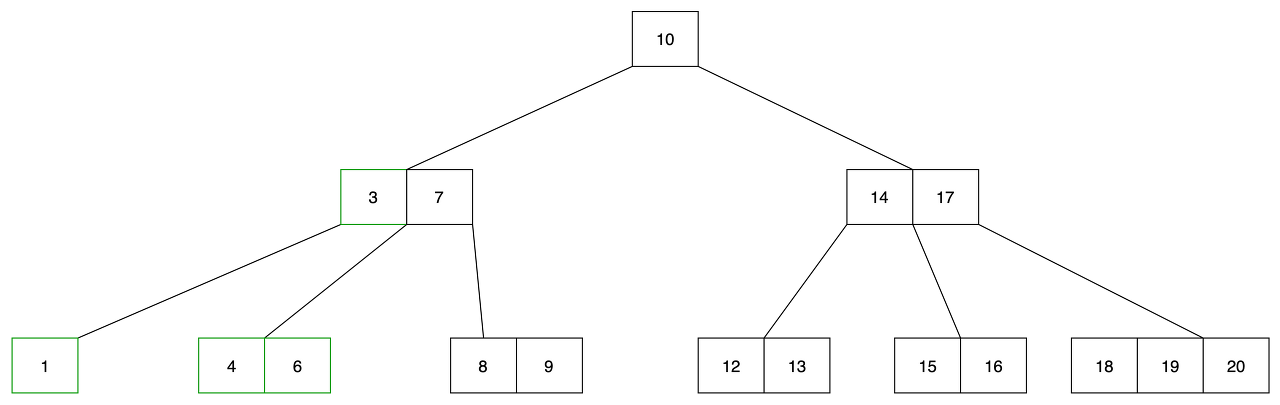
- 2를 삭제하고 합병을 진행합니다.
- undeflow가 발생한 노드(1), 부모 노드의 키(3), 형제 노드(4,6) 를 합병합니다.
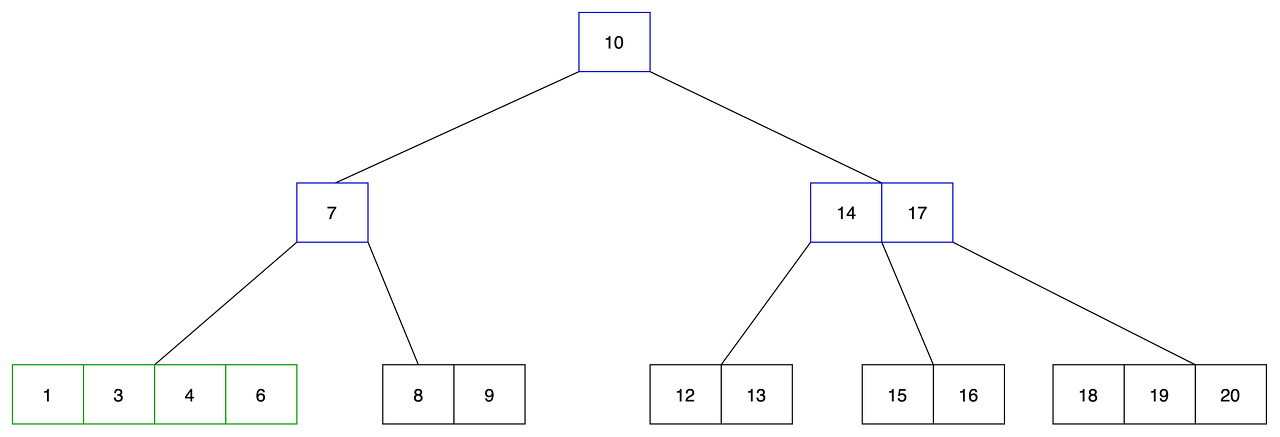
- 합병하여 1,3,4,6 이 하나가 된 노드를 생성하였습니다.
- 합병 과정에서 부모에 있는 3을 내렸으며, 이 과정에서 부모 노드의 키 갯수가 최소 키 갯수를 만족하지 못하게 됐습니다.
- 합병을 한번 더 진행해야 하며, undeflow가 발생한 노드(7), 부모 노드의 키(10), 형제 노드(14,17) 을 합병합니다.
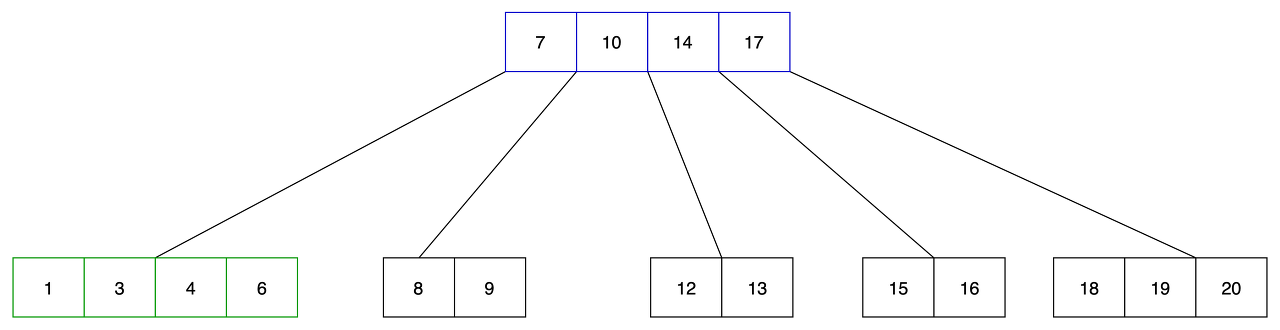
저장 가능한 키 갯수
- m차 btree의 각 레벨별로 저장 가능한 데이터 갯수는 다음과 같습니다.
level갯수
| root | m-1 |
| 2 | m(m-1) |
| 3 | m^2(m-1) |
| 4 | m^3(m-1) |
| h | m^(h-1) (m-1) |
- m-1은 하나의 키의 갯수 이며 m^(h-1) 은 노드의 갯수입니다.
- m차 btree에서 최대 저장 가능한 키의 갯수는 m^h - 1개가 됩니다.
B+ tree
B tree가 변형된 구조로 B tree와 유사하지만, leaf 노드가 모두 연결리스트로 구성되어 있어 범위 탐색이 가능하며, 범위 탐색 기능에 대해 높은 성능을 보장합니다.
특징
m 차 b+ tree를 기준으로 설명합니다.
- btree의 변형으로 인덱스 세트(index set)와 순차 세트(sequence set)로 구성됩니다.
- root와 leaf 노드를 제외한 모든 노드는 최소 m/2 - 1 개 최대 m 개의 서브 트리를 가집니다.
- 모든 leaf 노드들은 같은 레벨에 위치합니다.
- 한 노드 안에 있는 키 값들은 정렬된 상태를 유지합니다.
구성
인덱스 세트
인덱스 세트의 노드는 실제 데이터는 저장하지 않으며, 순차 세트에 있는 키 값을 찾아 갈 수 있는 경로만 제공합니다. 인덱스 세트에 저장된 데이터는 실제 값이 아니며, 순차 세트에 있는 키 값을 찾아 갈 수 있는 용도로만 사용합니다.
다음과 같은 특징을 갖습니다.
- 인덱스 세트도 B tree의 키 값들과 마찬가지로 정렬된 상태를 유지합니다.
- 내부 노드들이 인덱스 세트에 해당합니다.
순차 세트
순차 세트는 실제 데이터가 저장된 노드들입니다.
다음과 같은 특징을 갖습니다.
- leaf 노드들이 순차 세트에 해당됩니다.
- 인덱스 세트의 모든 키 값을 포함하지는 않습니다.
- 순차 세트의 키 값을 삭제해도 인덱스 노드의 키 값은 유지됩니다. 인덱스 세트의 노드는 순차 세트의 키 값을 찾아가기 위한 용도입니다. 순차 세트의 키 값을 삭제해도 인덱스 세트의 키 값을 찾아가기 위한 기능을 위해 인덱스 노드의 키 값은 유지될 수 있습니다.
- 인덱스 노드에 있는 키 값은 leaf 노드에 다시 나타날 수도 있고, 안 나타날 수도 있습니다. 순차 세트의 키 값 k 가 삭제된 경우 인덱스 노드에 유지되는 키 값 k는 leaf 노드에서 나타나지 않을 수 있습니다.
- 순차 세트의 노드는 연결리스트로 구성되어 있습니다.
B+ tree 예시
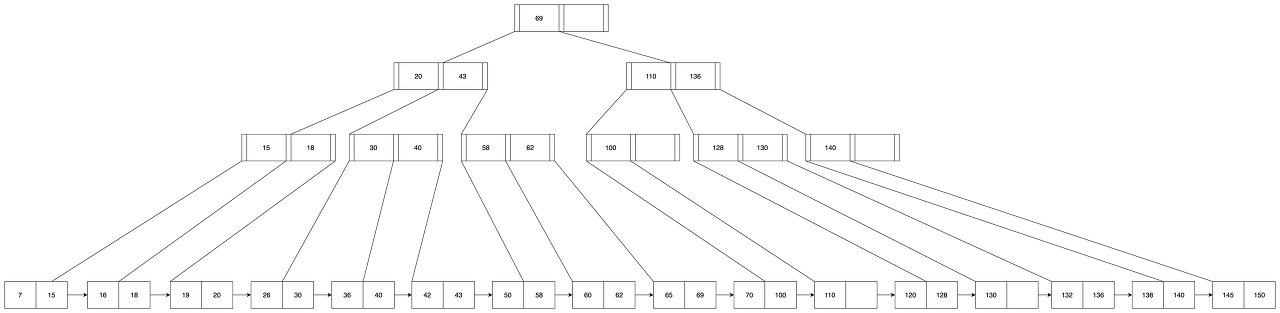
탐색
B tree와 마찬가지로 B+ tree도 탐색에 O(log(n)) 만큼의 시간 복잡도가 소요됩니다. 다만, B+ tree는 모든 leaf 노드가 연결리스트로 구성되어 범위 탐색에 효율적입니다.
N개의 데이터가 저장된 B tree에서 m(범위 i ~ j)개의 갯수에 대한 범위 검색을 한다고 가정합니다. B tree의 경우 하나의 데이터를 탐색하는데 O(log(n)) 만큼의 시간이 소요됩니다. 탐색을 m개의 데이터에 대해 반복해야 하므로 총 O(m*log(n)) 만큼의 시간이 소요됩니다.
B+ tree의 경우 leaf 노드가 연결리스트가 되어 있으므로
- 범위 검색에 대한 시작점 i를 탐색
- i 부터 j 까지 선형 탐색
두 가지 단계로 범위 탐색이 가능합니다.
B+ tree의 i 가 위치한 leaf 노드 까지 내려가는데 높이 만큼의 시간(log(N))이 소요됩니다. i 에서 j 까지 m개의 데이터에 대해 선형 탐색을 하므로 m 만큼의 시간이 소요됩니다. 따라서 범위 탐색에 대해 O(m + log(N)) 만큼의 시간 복잡도가 소요됩니다.